Mis-pronunciation Detection based on Phoneme Recognition
 Word-level MPD
Word-level MPD
Abstract
A Mis-pronunciation Detection (MPD) system. Mainly implemented the ICASSP 2020 paper SED-MDD: Towards Sentence Dependent End-To-End Mispronunciation Detection and Diagnosis. Some modifications are applied to improve the MPD performance. Moreover, I added an alignment module to obtain word-level alignment between the canonical phonemes (what the speaker should say) and the perceived phonemes (what the system recognized). Take a look at the audio demo.
Method
I implemented the system in the SED-MDD paper. Architecture is shown below.
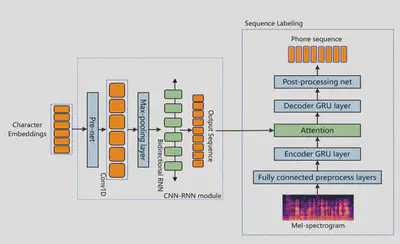
Modifications: The original SED-MDD system performs frame-wise phoneme prediction, in a fashion similar to an acoustic model. However I found that the predicted phonemes were quite noisy and could not match the results reported in the paper. Here I’m using a CTC loss to replace the original sequence labeling module. Also, I replace the Mel input representations with Wav2vec 2.0 representations. The Wav2vec 2.0 representations were extracted from a model which was unsupervisedly pre-trained on Librispeech and fine-tuned on the full 960 hours Librispeech audio.
Dataset
I use TIMIT and L2-ARCTIC, following the train/test split in SED-MDD.
Results (Audio Samples)
Take a look at the audio samples below!
Acknowledgement
This project is a collaboration with Shaojin Ding. The code was adapted from Shaojin Ding’s initial implementation.