Synthing: A WaveNet-based Singing Voice Synthisizer
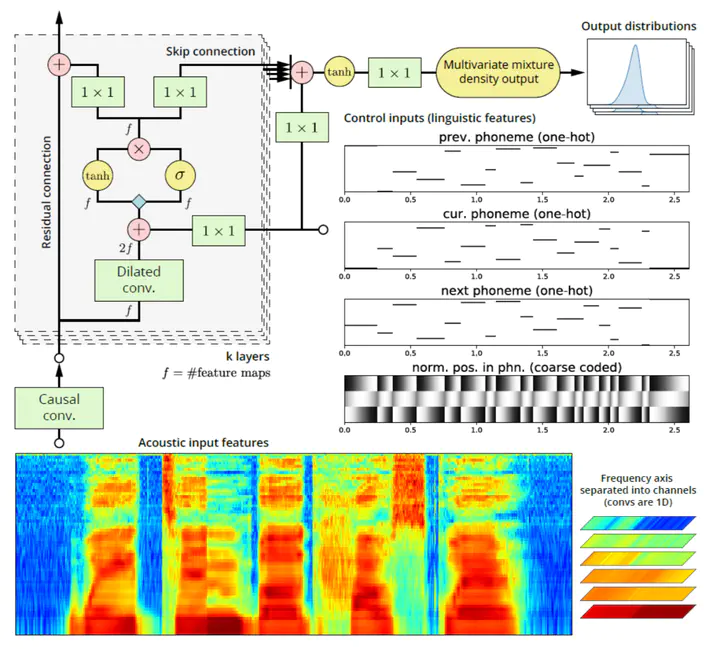 Timbre Model Architecture
Timbre Model Architecture
Abstract
Recent advances in synthesizing singing voice from a music score and lyrics have been achieved using a Neural Parametric Singing Synthesizer (NPSS) based on a modified version of the WaveNet architecture. This model trains on phonetic transcriptions of lyrics and acoustic features, and is able to significantly reduce training and generation times while still achieving the sound quality and naturalness of state-of-the-art concatenative systems. Although NPSS can model a specific singer’s voice and style of singing, it cannot generate a new singing performance given new singer data. SynthSing, our WaveNet-based singing synthesizer, expands on the NPSS synthesizer to generate a singer’s voice given new singing data and has the potential to transform the timbre of one singer’s voice into that of another singer. We found that the WaveNet-based model produces superior results in terms of naturalness and sound quality.
Method
We implemented the Timbre model mentioned in the framework of the NPSS paper.
Unlike the vanilla sample-to-sample WaveNet, the proposed model makes frame-to-frame predictions on 60-dimensional log-Mel Spectral Frequency Coefficients(MFSCs)and 4-dimensional Band Aperiodicity(AP) Coefficients, using F0(coarse coded), phoneme identity(one-hot coded) and normalized phoneme position(coarse coded) as local control inputs and singer identity as global control inputs. Then we feed generated MFSCs and APs, as well as true F0 into WORLD vocoder to synthesize audio. The features, i.e. MFSCs, APs and F0 are also extracted via WORLD.
For more details, take a look at our report and the original NPSS paper.
Dataset
We used two datasets: 1) NIT Japanese Nursery dataset (NIT-SONG070-F001) and 2) self-curated Coldplay songs dataset.
Results (Audio Samples)
Listen to some of our sythesized audio samples below!